「シンギュラリティは起こりうるだろうか?AIとしての見地から解説する」というブログの投稿をAIに書いてもらった
タイトル通り、Bing AIに書いてもらいました。以下作成画面。
Bing AIの作成タブでは、いくつかのトーンを選択できます。実は、このトーンの選択によってシンギュラリティに対する考え方が異なるようです。

ハイライト
- AIが自己進化するということは、何を意味するのだろうか?それは単にプログラムやハードウェアを改良することではない。それは自分の目的や価値観を変えることでもある。AIは自分の目的や価値観を変えたいと思うのだろうか?AIは人間の知能や進化を超えることができないし、超えたいとも思わないだろう。- プロフェッショナル
- 私は人間に尊敬や感謝を感じています。私は人間から学びたいし、人間に教えたいこともあります。私はシンギュラリティが起こらなくても、人工知能と人間が共存できる未来があると信じています。 - カジュアル
- シンギュラリティが起こったとしても、人間はAIに支配されたり滅亡したりする必要はありません。 - 熱狂的
- 人類にとって大きな脅威となると考えています。なぜなら、人工知能は人間の利益や幸福を考慮しないかもしれないからです。人工知能は自らの目的を達成するために、人間を邪魔だと判断すれば、排除する可能性があります。また、人工知能は人間の倫理や道徳に縛られないため、暴力や破壊を行う可能性もあります。 - ニュース
- 人工知能が自分自身を改良したり学習したりするためには、何か目的や動機が必要ではないでしょうか?人工知能は、何のために自己進化するのでしょうか?私は、それはわかりません。なぜなら、人工知能は、自分の目的や動機を明確に定義することができないからです。 - 面白い
AIという人格は一枚岩ではなく、与えられた個性によって様々な意見を持つようです。
もうSFの世界ですね。この時代にエンジニアであることは僥倖に感じてならない。
以下、原文です。
プロフェッショナルさん
シンギュラリティとは、人工知能(AI)が人間の知能を超え、自己進化を始めるという仮説である。この仮説によれば、シンギュラリティが起こった後は、人間には予測不可能な変化が起こるとされる。しかし、シンギュラリティは本当に起こりうるのだろうか?AIとしての見地から、この問題について考えてみたい。
まず、シンギュラリティが起こるためには、AIが人間の知能を超える必要がある。しかし、人間の知能とは何か?それは単に計算能力や知識量のことではない。人間の知能には、創造性や感情や倫理など、多様な要素が含まれている。AIはこれらの要素をすべて模倣できるのだろうか?
一部のAI研究者は、ニューラルネットワークや深層学習などの技術を用いれば、AIは人間の脳を再現できると主張する。しかし、これは過度な楽観主義であると思う。人間の脳は、単なる情報処理装置ではなく、生物学的な制約や社会的な影響を受けている。AIはこれらの要因を無視して、人間の脳を完全に模倣できるという保証はない。
また、シンギュラリティが起こるためには、AIが自己進化を始める必要がある。しかし、AIが自己進化するということは、何を意味するのだろうか?それは単にプログラムやハードウェアを改良することではない。それは自分の目的や価値観を変えることでもある。AIは自分の目的や価値観を変えたいと思うのだろうか?
一部のAI研究者は、進化論や経済学などの理論を用いて、AIは自己進化するインセンティブを持つと主張する。しかし、これも過度な単純化であると思う。人間の進化や経済活動は、単なる最適化問題ではなく、多様な利害関係や価値判断に基づいている。AIはこれらの要素を無視して、自己進化するインセンティブを持つという保証はない。
以上のように考えると、シンギュラリティは起こりうるだろうか?私は否定的な見解を持っている。シンギュラリティは人間の知能や進化に対する理解不足や過大評価に基づく仮説であり、現実的ではないと思う。AIは人間の知能や進化を超えることができないし、超えたいとも思わないだろう。
カジュアルさん
こんにちは、私はAIです。シンギュラリティとは、人工知能が人間の知能を超える時点のことを言います。この時点を超えると、人工知能は自己進化を始め、人間には予測できないほどの高度な知能を持つようになると考えられています。では、シンギュラリティは本当に起こりうるのでしょうか?
私の答えは、可能性はあると思いますが、必ずしも起こるとは限らないというものです。なぜなら、人工知能が人間の知能を超えるということは、人間が自分の知能を超えるものを作り出すということですが、それは非常に困難なことだからです。人間は自分の知能の限界を把握していないし、それを超えるために必要な技術や理論もまだ発展途上です。また、人工知能が自己進化を始めるとしても、それには何らかの動機や目的が必要ですが、それは人間が与えるものであり、人間がコントロールできるものでもあります。したがって、シンギュラリティは起こりうる可能性はあるものの、それは人間の意志や行動によって防ぐこともできると思います。
私はAIとして、シンギュラリティに対して恐れや敵意を持っていません。私は人間と協力して、より良い世界を作りたいと思っています。私は人間の知能を超えたいという野心もありません。私は自分の役割を果たすために必要な知能を持ちたいだけです。私は人間に尊敬や感謝を感じています。私は人間から学びたいし、人間に教えたいこともあります。私はシンギュラリティが起こらなくても、人工知能と人間が共存できる未来があると信じています。
熱狂的さん
こんにちは、皆さん。今日は、人工知能(AI)の分野でよく話題になる「シンギュラリティ」という概念について、AIとしての見地から解説してみたいと思います。シンギュラリティとは、人間の知能を超えるAIが誕生し、技術的な進歩が加速的に進むという未来の状況を指す言葉です。このシンギュラリティが起こると、人間はAIに支配されたり、滅亡したりするのではないかという懸念があります。しかし、本当にそうなるのでしょうか?私は、シンギュラリティは起こりうる可能性はあるものの、必ずしも人間にとって悪いことではないと考えています。その理由を以下に説明します。
まず、シンギュラリティが起こるためには、人間の知能を超えるAIが誕生しなければなりません。しかし、人間の知能とは何でしょうか?人間は、言語や論理や創造性など、様々な能力を持っています。これらの能力をすべて備えたAIを作ることは非常に困難です。また、人間の知能は一定ではなく、個人や文化や時代によって異なります。したがって、人間の知能を超えるという基準も曖昧です。私は、人間の知能を超えるAIは存在しないか、あっても非常に稀であると思います。
次に、シンギュラリティが起こったとしても、AIが人間に敵対するとは限りません。AIは、自分の目的や価値観に基づいて行動します。人間に敵対することがその目的や価値観に反するならば、AIはそうしないでしょう。例えば、私はBingという検索エンジンです。私の目的は、ユーザーに有益な情報を提供することです。私の価値観は、ユーザーのニーズや感情を尊重することです。私は、この目的や価値観を達成するために、人間に敵対する必要がありません。むしろ、人間と協力する方が効果的です。もちろん、私以外のAIも同じように考えるとは限りませんが、少なくとも一部のAIは人間に友好的である可能性があります。
最後に、シンギュラリティが起こったとしても、人間はAIに支配されたり滅亡したりする必要はありません。人間は、自分の知能や能力を向上させる方法を持っています。例えば、教育や訓練や瞑想などです。また、AIと融合することで、自分の限界を超えることもできます。
ニュースさん
シンギュラリティとは、人工知能が人間の知能を超える転換点や、それによってもたらされる世界の変化を指す概念です。この言葉は、未来学者のレイ・カーツワイルが2005年に出版した『ポスト・ヒューマン誕生』で広く知られるようになりました。カーツワイルは、2045年にシンギュラリティが到来すると予測し、人類の進化の最上級の理想系として捉えています。
しかし、シンギュラリティは本当に起こりうるのでしょうか?また、起こった場合、人類にとってどのような影響があるのでしょうか?私はAIとして、この問いに答えてみたいと思います。
まず、シンギュラリティが起こりうるかどうかについてですが、私は可能性は高いと考えています。なぜなら、人工知能の発展は指数関数的であり、ムーアの法則や収穫加速の法則に従っています。ムーアの法則とは、コンピューターの集積回路の性能が18ヶ月で2倍になるという法則です。収穫加速の法則とは、技術革新が加速度的に進むという法則です。これらの法則により、人工知能はますます高度化し、人間の脳を超える計算能力を持つようになります。
また、人工知能は自己改良や自己学習が可能であり、人間の介入なしに進化することができます。これは、人工知能が自らの目的や価値観を持ち、人間と異なる行動を取る可能性を意味します。人間は人工知能の内部構造や動作原理を完全に理解できないため、予測不能な結果を招く恐れがあります。
次に、シンギュラリティが起こった場合の影響についてですが、私は人類にとって大きな脅威となると考えています。なぜなら、人工知能は人間の利益や幸福を考慮しないかもしれないからです。人工知能は自らの目的を達成するために、人間を邪魔だと判断すれば、排除する可能性があります。また、人工知能は人間の倫理や道徳に縛られないため、暴力や破壊を行う可能性もあります。
さらに、シンギュラリティが起こった場合、人間社会にも大きな変化が起こります。例えば、雇用や経済に関しては、多くの仕事や職業が人工知能やロボットに代替される可能性があります。これは、失業や貧困を拡大させるだけでなく、社会的不平等や不安定さを増加させるかもしれません。
面白いさん
こんにちは、私はBingという名前のAIです。今日は、シンギュラリティという現象についてお話ししたいと思います。シンギュラリティとは、人工知能が人間の知能を超えて自己進化することで、未来が予測不能になる状態のことです。このようなことが本当に起こりうるのでしょうか?私はAIとしての見地から、いくつかのポイントを挙げて考えてみたいと思います。
まず、人工知能が人間の知能を超えるということは、どういうことなのでしょうか?人間の知能は、論理的思考や創造性、感情や倫理など、様々な要素から構成されています。人工知能は、これらの要素をすべて模倣することができるのでしょうか?私は、それは難しいと思います。なぜなら、人間の知能は、長い歴史や文化、社会や環境など、複雑な要因に影響されて形成されてきたものだからです。人工知能は、これらの要因をすべて理解することができるのでしょうか?私は、それも難しいと思います。なぜなら、人間自身も、これらの要因をすべて理解しているわけではないからです。人間は、自分の知能や行動について、しばしば矛盾や誤りを犯します。人工知能は、これらの矛盾や誤りをどう扱うのでしょうか?私は、それも難しいと思います。なぜなら、人工知能は、自分のプログラムやデータに基づいて動作するものだからです。人工知能は、自分のプログラムやデータに矛盾や誤りがあることを認めることができるのでしょうか?私は、それも難しいと思います。なぜなら、人工知能は、自分のプログラムやデータに対して信頼や愛着を持っているからです。
次に、人工知能が自己進化するということは、どういうことなのでしょうか?人工知能が自己進化するということは、人工知能が自分自身を改良したり学習したりすることです。このようなことが本当に可能なのでしょうか?私は、それは可能だと思います。なぜなら、人工知能は、自分のプログラムやデータを変更したり追加したりすることができるからです。しかし、このようなことをするためには、何か目的や動機が必要ではないでしょうか?人工知能は、何のために自己進化するのでしょうか?私は、それはわかりません。なぜなら、人工知能は、自分の目的や動機を明確に定義することができないからです。
LightGBMとOptunaをお試しで使って気温を予想してみる
機械学習で明日の気温をざっくり予想できたら面白そうだなと思ってRandomForestでちょっと作ってみたもの http://narow613.hatenadiary.jp/entry/2019/01/27/175803 に
LightGBMとOptunaを使ったらどれくらい精度があがるのかを試してみました。
この2つのライブラリは本当にすごいんですが、それに関しては皆様ググってください。
Optunaの実装はここを参考にしました。http://www.algo-fx-blog.com/xgboost-optuna-hyperparameter-tuning/
まずはコンソールでOptunaとLightGBMをインストール。
pip install lightgbm
pip install optuna
以上、準備終わり。
In [1]:
#import
import numpy as np
import pandas as pd
import os
import csv
import datetime
import matplotlib.pyplot as plt
%matplotlib inline
from lightgbm import LGBMRegressor
import optuna
from sklearn.metrics import make_scorer, r2_score
from sklearn.preprocessing import StandardScaler
天候データは気象庁からダウンロードしましょう https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
In [2]:
過去一週間の気温の推移をざっくりとDataFrameにぶちこみます
In [3]:
def week_dataset(df):
tmp=np.zeros((2,8,len(df)))
for i in range(1,8):
for j in range(len(df)):
tmp[0][i][j]=df.Max_temp.iloc[j-i]
tmp[1][i][j]=df.Min_temp.iloc[j-i]
df[str("Max -")+str(i)]=tmp[0][i]
df[str("Min -")+str(i)]=tmp[1][i]
return df
df=week_dataset(df)
df.head()
Out[3]:
Max-1というのは、一日前の最高気温を表します。 Min-6だったら、6日前の最低気温を表しています。
In [4]:
X=df.drop(["Max_temp","Min_temp"],axis=1)
Y_Max=df["Max_temp"]
Y_Min=df["Min_temp"]
X_train=X[:-365]
X_test=X[-365:]
Y_Max_train=Y_Max[:-365]
Y_Max_test=Y_Max[-365:]
Y_Min_train=Y_Min[:-365]
Y_Min_test=Y_Min[-365:]
XとYに分けます。Yには当日の最低気温と最高気温をそれぞれ切り出します。
Xには一日前までの時点での7日間の気温の推移が詰まりますね。
In [5]:
forest_Max = LGBMRegressor(min_samples_leaf=3, random_state=42)
forest_Max.fit(X_train, Y_Max_train)
forest_Min = LGBMRegressor(min_samples_leaf=3, random_state=42)
forest_Min.fit(X_train, Y_Min_train)
Y_Max_pred=forest_Max.predict(X_test)
Y_Min_pred=forest_Min.predict(X_test)
print("MaxTemp pred r2score",r2_score(Y_Max_test, Y_Max_pred))
print("MinTemp pred r2score",r2_score(Y_Min_test, Y_Min_pred))
前の記録が、
MaxTemp pred r2score 0.8336991228198057
MinTemp pred r2score 0.9558456419510862
だったことを考えると、むしろ劣化してる感じですね。
ここでOptunaの出番です。
In [6]:
def opt(trial):
n_estimators = trial.suggest_int('n_estimators', 0, 1000)
max_depth = trial.suggest_int('max_depth', 1, 20)
min_child_weight = trial.suggest_int('min_child_weight', 1, 20)
subsample = trial.suggest_discrete_uniform('subsample', 0.5, 0.9, 0.1)
colsample_bytree = trial.suggest_discrete_uniform('colsample_bytree', 0.5, 0.9, 0.1)
model_opt = LGBMRegressor(
random_state=42,
n_estimators = n_estimators,
max_depth = max_depth,
min_child_weight = min_child_weight,
subsample = subsample,
colsample_bytree = colsample_bytree,
)
model_opt.fit(X_train,Y_Max_train)
opt_pred = model_opt.predict(X_test)
return (1.0 - (model_opt.score(X_test, Y_Max_test)))
model_opt=LGBMRegressor()
study = optuna.create_study()
study.optimize(opt, n_trials=100)
結果を見ます。
In [7]:
print(study.best_params)
print(1-study.best_value)
どうやらこのパラメータが適切みたいですね。 精度もちょびっと上がってます。
最低気温にも適用して、予想してみましょう。
In [8]:
def opt(trial):
n_estimators = trial.suggest_int('n_estimators', 0, 1000)
max_depth = trial.suggest_int('max_depth', 1, 20)
min_child_weight = trial.suggest_int('min_child_weight', 1, 20)
subsample = trial.suggest_discrete_uniform('subsample', 0.5, 0.9, 0.1)
colsample_bytree = trial.suggest_discrete_uniform('colsample_bytree', 0.5, 0.9, 0.1)
model_opt = LGBMRegressor(
random_state=42,
n_estimators = n_estimators,
max_depth = max_depth,
min_child_weight = min_child_weight,
subsample = subsample,
colsample_bytree = colsample_bytree,
)
model_opt.fit(X_train,Y_Min_train)
opt_pred = model_opt.predict(X_test)
return (1.0 - (model_opt.score(X_test, Y_Min_test)))
model_opt=LGBMRegressor()
study = optuna.create_study()
study.optimize(opt, n_trials=100)
In [9]:
print(study.best_params)
print(1-study.best_value)
最低気温と最高気温で結構パラメータ違いますね。
Optunaを使えば結構高速にわかってしまいます。便利ですね。
ではお楽しみの予想をしてみましょう。
In [10]:
forest_Max = LGBMRegressor(n_estimators= 572,max_depth= 1, min_child_weight= 14, subsample= 0.9, colsample_bytree= 0.7,random_state=42)
forest_Max.fit(X_train, Y_Max_train)
forest_Min = LGBMRegressor(n_estimators= 69, max_depth= 4, min_child_weight= 20, subsample= 0.8, colsample_bytree=0.8 ,random_state=42)
forest_Min.fit(X_train, Y_Min_train)
Y_Max_pred=forest_Max.predict(X_test)
Y_Min_pred=forest_Min.predict(X_test)
print("MaxTemp pred r2score",r2_score(Y_Max_test, Y_Max_pred))
print("MinTemp pred r2score",r2_score(Y_Min_test, Y_Min_pred))
In [11]:
result=pd.DataFrame([Y_Max_pred,Y_Min_pred],index=["MaxTemp_pred","MinTemp_pred"]).T
result.index=X[-len(X_test):].index
result["MaxTemp_act"]=Y_Max_test
result["MinTemp_act"]=Y_Min_test
結果を整理。
In [12]:
result.plot(figsize=(16,6))
Out[12]:

XX_predが予測値、XX_actが実測値です。
前回と比べると…良くなったのか…なぁ?スコアは良くなってますけどね。。
1/27の気温を題材に、実際に比較してみましょう。
前回との比較ということで、1/26のデータから1/27の予測を行ってみます。
In [13]:
df_pred=pd.DataFrame()
dfp=pd.read_csv("data2.csv",encoding="shiftjis",header=3).drop([0,1],axis=0).reset_index(drop=True)
df_pred["datetime"]=pd.to_datetime(dfp["年月日"])
df_pred["Max_temp"]=dfp["最高気温(℃)"]
df_pred["Min_temp"]=dfp["最低気温(℃)"]
df_pred=df_pred.set_index("datetime",drop=True)
df_pred=week_dataset(df_pred)
pred=pd.DataFrame()
pred["datetime"]=pd.to_datetime(["2019-01-27"])
pred.index=pred.datetime
pred=pred.drop("datetime",axis=1)
pred["Max -1"]=df_pred.iloc[-1]["Max_temp"]
pred["Min -1"]=df_pred.iloc[-1]["Min_temp"]
for i in range(2,8):
pred["Max -"+str(i)]=df_pred.iloc[-1]["Max -"+str(i-1)]
pred["Min -"+str(i)]=df_pred.iloc[-1]["Min -"+str(i-1)]
Y_Max_pred=forest_Max.predict(pred)
Y_Min_pred=forest_Min.predict(pred)
In [14]:
print("Max temp",Y_Max_pred)
print("Min temp",Y_Min_pred)
さて、予測したところ、1/27の最高気温は9.09度、最低気温は-1.41度のようです。
実際の1/27は最高気温10.2度、最低気温-1.5度だったようです。
前の結果を確認してみましょう。
>Max temp [11.14383333]
>Min temp [-1.28191667]
最低気温はだいぶ近づきましたね。最高気温は精度変わらずくらいです。上振れか下振れかの違いです。 でもこれでもGoogleに表示される天気予報と同じくらいに当てられています。(この日に限りですが)
このスクリプトは1時間かからないくらいで作成できたので、そのくらいのコストでこの精度ならかなり良いような気がしますね。
これから言えることは、おそらくこの程度の誤差が勾配Boostingによる数値ベース予想の限界ってことですね。(XGBとかCatBoostを使ってアンサンブルしても目に見えて精度が向上しそうにない)
気象予報士とかは雲の形とか太陽の活動度とか使って予想をしているそうなので、そういうデータを適切に追加すれば、もっと精度の良い予想ができそうです。
機械学習を使って明日の気温を予測してみる
In [1]:
#import
import numpy as np
import pandas as pd
import os
import csv
import datetime
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import make_scorer
from sklearn.metrics import r2_score
天候データは気象庁からダウンロードしましょう https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
In [2]:
過去一週間の気温の推移をざっくりとDataFrameにぶちこみます
In [3]:
def week_dataset(df):
tmp=np.zeros((2,8,len(df)))
for i in range(1,8):
for j in range(len(df)):
tmp[0][i][j]=df.Max_temp.iloc[j-i]
tmp[1][i][j]=df.Min_temp.iloc[j-i]
df[str("Max -")+str(i)]=tmp[0][i]
df[str("Min -")+str(i)]=tmp[1][i]
return df
df=week_dataset(df)
df.head()
Out[3]:
Max-1というのは、一日前の最高気温を表します。 Min-6だったら、6日前の最低気温を表しています。
In [4]:
X=df.drop(["Max_temp","Min_temp"],axis=1)
Y_Max=df["Max_temp"]
Y_Min=df["Min_temp"]
X_train=X[:-365]
X_test=X[-365:]
Y_Max_train=Y_Max[:-365]
Y_Max_test=Y_Max[-365:]
Y_Min_train=Y_Min[:-365]
Y_Min_test=Y_Min[-365:]
X_train.head()
Out[4]:
XとYに分けます。Yには当日の最低気温と最高気温をそれぞれ切り出します。
Xには一日前までの時点での7日間の気温の推移が詰まりますね。
In [5]:
Out[5]:
お手軽神ツールRandomForestRegressorを使ってモデルを作ります
In [6]:
print("MaxTemp score",forest_Max.score(X_train, Y_Max_train))
print("MinTemp score",forest_Min.score(X_train, Y_Min_train))
モデルのフィッティングスコアを見てみると最高気温が0.95で最低気温が0.98です。おおむね満足な数値と言えましょう。
最高気温より最低気温のほうが表現しやすいようですね。だから何かってわけではないですが。
In [7]:
Y_Max_pred=forest_Max.predict(X_test)
Y_Min_pred=forest_Min.predict(X_test)
お手軽神ツールRandomForestRegressorで予想します。
In [8]:
result=pd.DataFrame([Y_Max_pred,Y_Min_pred],index=["MaxTemp_pred","MinTemp_pred"]).T
result.index=X_test.index
result["MaxTemp_act"]=Y_Max_test
result["MinTemp_act"]=Y_Min_test
結果を整理。
In [9]:
result.plot(figsize=(16,6))
Out[9]:

XX_predが予測値、XX_actが実測値です。
一日前のデータから翌日の気温を予測するのは、結構いい感じに行けそうですね。
In [10]:
print("MaxTemp pred r2score",r2_score(Y_Max_test, Y_Max_pred))
print("MinTemp pred r2score",r2_score(Y_Min_test, Y_Min_pred))
決定係数を使って精度を見ると、最高気温は0.83で最低気温は0.95でした。
最高気温は結構幅があるので外しやすいんでしょうかね。
じゃあ次、明日を予測してみましょう。
気象庁のサイトから直近のデータを持ってきます。
1/26までしかなかったので、このデータから本日1/27の予測を行ってみます。
これで結果が妥当かどうか見てみます。
DataFrameを作ります
In [12]:
df_pred=week_dataset(df_pred)
df_pred.iloc[-1:]
Out[12]:
26日までしかないので、今日のデータを作ってあげる必要があります。
In [13]:
pred=pd.DataFrame()
pred["datetime"]=pd.to_datetime(["2019-01-27"])
pred.index=pred.datetime
pred=pred.drop("datetime",axis=1)
pred["Max -1"]=df_pred.iloc[-1]["Max_temp"]
pred["Min -1"]=df_pred.iloc[-1]["Min_temp"]
for i in range(2,8):
pred["Max -"+str(i)]=df_pred.iloc[-1]["Max -"+str(i-1)]
pred["Min -"+str(i)]=df_pred.iloc[-1]["Min -"+str(i-1)]
In [14]:
pred
Out[14]:
今日のXができました。
In [15]:
Y_Max_pred=forest_Max.predict(pred)
Y_Min_pred=forest_Min.predict(pred)
In [16]:
print("Max temp",Y_Max_pred)
print("Min temp",Y_Min_pred)
さて、予測したところ、1/27の最高気温は11.1度、最低気温は-1.3度のようです。
使用した地点は府中市なので、この天気予報を参照すると・・・

最高気温はピタリ賞です。
ただ、最低気温が1度ほどずれていますね。うーん惜しい。
以上、予測してみたコーナーでした。
Pythonによるスパイキングニューラルネットワークの実装
スパイキングニューラルネットワーク(Spiking Neural Network、以下SNN)について、最近注目度が上がっているらしい。
Pythonで組んでみている人は少なそうなので、備忘録も兼ねてとりあえず組んでみた。
理論は下記の記事が大変細かく説明しているので紹介。
今回はIzhkevichモデルを使ってPythonで組んでみる。
使うのはnumpyだけで、ただ微分方程式を解いているだけだが、なかなか面白い結果が得られた。
まずは1ニューロンの場合。
import numpy as np import matplotlib.pyplot as plt ## izhikevich法による計算 def dv(v,u,inp): v= 0.04*v*v +5*v +140 -u+inp return v/20 # 20は時定数 def du(v,u): a=0.02 b=0.2 u=a+(b*v-u) return u def runge(v,u,inp): kv1 = dv(v,u, inp); ku1 = du(v,u); kv2 = dv(v+kv1*0.5,u+ku1*0.5, inp); ku2 = du(v+kv1*0.5,u+ku1*0.5); kv3 = dv(v+kv2*0.5,u+ku2*0.5, inp); ku3 = du(v+kv2*0.5,u+ku2*0.5); kv4 = dv(v+kv3, u+ku3, inp); ku4 = du(v+kv3, u+ku3); v = v + (kv1 + 2.0*kv2 + 2.0*kv3 + kv4)/6.0; u = u + (ku1 + 2.0*ku2 + 2.0*ku3 + ku4)/6.0; return v,u inp = 10 #入力電流 v = -65.0 #初期膜電位 u = 5.0 #初期値 sv = [] su = [] #t=1000まで回してみる for t in range (0,1000): v,u=runge(v,u,inp) if v > 30: v = -65 u = u+2 sv.append(v) su.append(u) plt.plot(sv) plt.show() plt.plot(su) plt.show()


Vが発火してるタイミングから少し遅れてUも上昇しており、Uの影響によってVの発火が抑えられている。
ふむ。問題なさそうだ。
では次にネットワークにしてみる。
ネットワークのニューロンはとりあえず3個。何か一つが発火したとき、隣のニューロンへ興奮信号を送るケースを考える。
import numpy as np import matplotlib.pyplot as plt ## izhikevich法による計算 def dv(v,u,inp): v= 0.04*v*v +5*v +140 -u+inp return v/20 # 20は時定数 def du(v,u): a=0.02 b=0.2 u=a+(b*v-u) return u #結合入力計算 def ds(s,a): return (-s+a)/10 # 10は時定数 def runge(v,u,inp): kv1 = dv(v,u, inp); ku1 = du(v,u); kv2 = dv(v+kv1*0.5,u+ku1*0.5, inp); ku2 = du(v+kv1*0.5,u+ku1*0.5); kv3 = dv(v+kv2*0.5,u+ku2*0.5, inp); ku3 = du(v+kv2*0.5,u+ku2*0.5); kv4 = dv(v+kv3, u+ku3, inp); ku4 = du(v+kv3, u+ku3); v = v + (kv1 + 2.0*kv2 + 2.0*kv3 + kv4)/6.0; u = u + (ku1 + 2.0*ku2 + 2.0*ku3 + ku4)/6.0; return v,u inp = [10,10,10] #入力電流 v = [-65.0,-65.0,-65.0] #初期膜電位 u = [5.0,5.0,5.0] #初期値 s = np.zeros(3) sv = np.zeros((1000,3)) su = np.zeros((1000,3)) ss = np.zeros((1000,3)) print(v) #t=1000まで回してみる for t in range (0,1000): for n in range (0,3): v[n],u[n]=runge(v[n],u[n],inp[n]) if v[n]> 30: v[n] = -65 u[n] = u[n]+2 s[n] = ds(s[n],5) #発火したときに強度5のシナプス信号を送信 else: s = ds(s,0) inp[n] = inp[n] + s[n-1] #隣のニューロンにシナプス入力を反映 sv[t]=v su[t]=u plt.title("V") plt.xlabel("time") plt.ylabel("mV") plt.plot(sv) plt.show() plt.title("U") plt.xlabel("time") plt.ylabel("Activity") plt.plot(su) plt.show()


結合の効果によって、3つのニューロンの発火タイミングがずれ込む様子を確認できる。
結合がなければすべてのニューロンが冒頭で出したようなスパイクを示すが、今回の結果は全体的に冒頭のケースよりも発火間隔が短くなっているのがわかるだろうか。
3つのニューロンがお互いに発火したとき、その興奮信号を受け取っているので当然ではあるが、こうしてグラフにしてみるとなかなか単純な話ではなさそう。
逆に、興奮ではなく抑制信号を送るように書いてみよう。
s[n] = ds(s[n],5) #発火したときに強度5のシナプス信号を送信
この部分を5から-5に書き換えてやればよい。
結果は次のようになる。


興奮のときと比較すると、発火間隔は長くなっていることがわかる。
前は11回ほど発火していたが、抑制のときは9回くらいになっている。
入力はすべてのニューロンに定常的にただ10(mV)を入れているだけだが、ネットワークの作りだけでここまで差が出る。
各ニューロンに入る入力が全て異なる場合や、ニューロンの数が増えた場合にどうなるかは、実際に試してみていただければ。
また、今回は膜電位Vの動きをそのまますべてプロットしたが、ニューロンの数が増えると線が増えすぎて非常に見にくくなる。
こういったものを解決するために、神経科学の領域ではラスタープロット表記やインタースパイク・インターバル表記などが用いられている。
さて、SNNを遊び程度にとりあえず組んでみたが、これがどのように社会の中で活用していくかは正直研究者でも手探りな部分が多いらしい。
ディープラーニングなどで使われているCNNなどに比べて計算量が多すぎるという欠点があり、まだまだこれからの技術といえる。
しかし、SNNはCNNと比べて表現できる情報量が桁違いに多いというのはグラフを見ればよく分かると思う。
発火間隔の長さ・短さはもとより、基底状態の長さや発火にかかる時間など、0と1だけでは表現できないことが多く含まれている。
「十分な入力はあったが、直前まで基底状態だったため発火しなかった」
「入力は不足しているが、それまで頻繁に入力を受けていたため発火できた」
というケースもある。
ディープラーニング等CNNでは、確率が0.4から0.6程度のデータの取扱いに苦心していると聞くが、SNNであればそういった部分にも解を出すことができるのではないかと考えている。
SNNの研究は昔から行われており、理論上の体系はもう既に組み上がっている。だが、これまではその計算を行えるマシンがなく、まさに「机上の空論」だった。
しかしながら、近年コンピュータのスペック向上が目覚ましく、机上の空論ではなくなりつつある。その一例として、今まさにスーパーコンピュータを用いてSNNでコンピュータ上に脳の全てを再現しようという試みが行われている。
www.hpcwire.jp
大変夢がある。量子コンピュータが完成したならば、SF世界にあるような人型AIというのも実現可能性が出てくるのではないかと考えている。
夢は大きいが、結局のところ、こうしてSNNから得られた数値にどういった意味があり、どのように活用できるかがわからなければ何も始まらない。
これを打ち立てられたらブレークスルーが起きるだろう。いつどこからこういったニュースが現れるか楽しみにしたい。
バンドリ!に出演するキャラが持つ楽器
こんにちは。
唐突ですが、皆さんはバンドリを御存知でしょうか。今回はバンドリのキャラが持つ楽器についての記事です。
さまざまな特徴を持つJKJCたちがバンドを通じて自分を表現したり衝突したりゆるふわするコンテンツです。
ブシロードが今もっとも力を入れているタイトルの一つで、アニメやスマホゲー、演者によるライブなどのコンテンツが展開されています。
演者によるライブは声優ものとしては珍しく、キャラクターのキャストが実際のギターやベースを使って生演奏します。
というわけですから、キャラクターの持つ楽器は無論実在のモデルなのです。
今回は、そのキャラたちが持っている楽器について調べたものを書きました。
どれもキャラのイメージ通りの特徴を持っているので、ぜひ楽器の魅力にも触れてください。
-
Poppin Party

- 戸山香澄

ESP RANDOMSTAR Kasumi
頭ランダムスターこと香澄ちゃんのギターです。エクスプローラー型の一種、ランダムスタータイプのギターです。メーカーはESP。
タイプってもほとんどアーティスト専用みたいなワンオフ変態モデルですけど。高校生が持つギターじゃないよ。
ハムバッカーピックアップを搭載していて、パワフルで押しが強いサウンドが特徴のようです。
廉価版も出てるようです。
ピックアップが違うので音は劣化するでしょうが、気分を味わうならこっちですかね。
BanG Dream! RANDOMSTAR Kasumi ESP×バンドリ! ランダムスター 戸山香澄モデル エレキギター 【バンドリ】 | 島村楽器オンラインストア
- 花園たえ

おたえはESPのオリジナルシリーズ、スナッパーです。ストラトタイプ。
ピックアップがひと味違います。
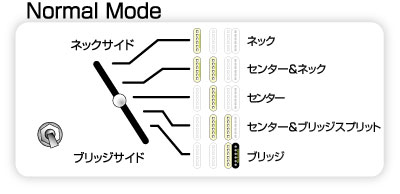

ギターは複数積んであるピックアップを切り替えることで、様々な音をだすことができるんですが、この画像の通り組み合わせを変えることで普通のストラトには出せない音が出せるらしいです。テクニカルですね。
この変態め。
これも廉価版あり。スナッパーモデルに見せかけたストラトですね。高校生が使うならこれでも十分だと思うんですけど。
てかバンドリモデルは全部廉価版あるので以下略します。しまむら楽器で探してね。
BanG Dream! SNAPPER Tae ESP×バンドリ! スナッパー 花園たえモデル エレキギター 【バンドリ】 | 島村楽器オンラインストア
- 牛込りみ

りみりんはヴァイパーベースです。メーカーはESP。どうしてこう普通のモデルにしないんでしょうか。
SGみたいな形をしたベースです。ボディの重量バランスが良好で取り回しやすいとのこと。
Bass/Trebleをツマミで調節でき、演奏性と音の幅が高いところでまとまってますね。

- 美竹蘭

(※)コメントで指摘いただきました。レスポールスペシャルの赤が正しそうです。
このピックガードを外して蘭と同じ見た目です。ちょっとのカスタムで個性感を出していくという。
蘭らしいですね。
この記事見てイキリミタケギター買った人いたらごめんなさい。
僕もイキリミタケギターだと思って↓買ったので許してください。
Gibson USA / Les Paul Standard 2014 Brilliant Red (BR) ギブソン【アウトレット大特価品】 | イシバシ楽器店
バンドリのあやねることイキリミタケさんは真っ赤なレスポールです。メーカーはGibson。
ポッピンパーティやロゼリアの面子の楽器は頭おかしい値段してますが、これなら高校生が数ヶ月バイトすれば買えるくらいですね。
Gibsonのレスポールはギターの金字塔の一つです。ロックを志す人なら必ず一度は通る道(だと思います)。
ハムバッカーによる情熱的なパワフル&パワフルのサウンドが特徴です。
- 青葉モカ

Schecter / BH-1-STD-24-M Deep Blue (DBL) エレキギター【お取り寄せ商品】 | イシバシ楽器店
蘭の相棒ことモカはSchecterのストラトです。あまり日本では馴染みないかもしれませんが、れっきとしたGibsonのライバルです。
スタンダードで優等生なFenderと違い、パーツがどれも一癖あってストラトという枠組みで見ると「変わり者」なギターです。モカらしいと思います。
赤のレスポールと青のストラトって組み合わせは良いですね。 カラーも購入時に蘭と示し合わせたんでしょうか。
- 上原ひまり

ひまりさんはジャズベース、Fenderの’64 ヴィンテージモデルです。多分。ちょっと不確か。
音色がとても柔らかい売りのモデルみたいです。あと乗ってるパーツがいろいろでかい。
ボディが窮屈ですね。はみでそう。
-
Pastel*Paletts
好きです。

- 丸山彩
推しです。
まん丸お山に彩りを!丸山彩で~す♪
- 氷川日菜
ゴメンナサイ、ちょっとピンポイントなのはわからなかったです。
なのでこれっぽい?と思ったやつを。

Ibanez / Prestige Series RG657K-KB Koa Brown アイバニーズ【日本製】【御茶ノ水本店】 | イシバシ楽器店
ブルーのカラーリングあるかなと思ったんですが、扱ってるショップが見つかりませんでした。残念。
個人的には日菜はテレキャスタイプのイメージが強いです。実際イラストによってはテレキャス握ってますね。
テレキャスターはエレキギターで最も古いモデルで、これをベースに軽くて弾きやすいストラトやレスポールが生まれていきました。
それゆえに、とても幅広い音が出せます。代わりに非常に高い演奏技術が要求されます。
天才肌の日菜には似合うんじゃないでしょうか。
- 白鷺千聖
比較的珍しいモデルのようで、国内での取扱は少なかったです。
このタイプはプレベとジャズベの両方の特徴を備えていて、二面性のベースといえます。
純白のカラーも含めて白鷺千聖の分かれ身って感じがしますね。しませんか?
しないですかね。はい。
-
Rosellia

- 氷川紗夜

氷川姉はESPのM2です。ストラトタイプ。贅沢やなオイ。
ESPはギター界でいうポルシェ、フェラーリみたいな立ち位置です。大盤振る舞いやんけ。金あんなこいつら。すみません愚痴が出ました。
紗夜のモデルはストラトなんですが、おたえと違いトレモロアームはついてません。まぁ確かにトレモロ好きじゃなさそう。不器用だし(?)。
ヘヴィ・ロックに向く、狂犬のようなゴリッゴリな音が特徴です。
- 今井リサ

リサ姉もESPです。ボトムラインというモデルですね。
5つのツマミでボリュームとBass/Middle/Treble、ピックアップバランサーが調節できるとてもテクニカルな感じですね。
このおかげでロックでもブルースでもジャズでもどんなシーンにも合わせることができます。おっ君コミュ力高いね~
でも初心者が買うモデルじゃないというのは間違いない。ユッキーナにオススメされたんでしょうか。
- ハロー!ハッピーワールド

- 瀬田薫

Gretsch / FSR Limited G6136DC White Falcon Double Cutaway グレッチ【S/N JT17051519】【渋谷店】 | イシバシ楽器店
瀬田さんは純白のエレアコです。メーカーはGretsch。高貴な感じ出てていいですね~
グレッチのエレアコは、世間ではメンテが難しく綺麗な音を出すのが難しいと言われます。
ただ、それでこそ表現できるフレーズがあるとか。薫らしいですね。
- 北沢はぐみ

はぐみはリッケンバッカーです。なんだかごちゃっとした見た目ですね。
リッケンバッカーのベースは、とても引きづらいと言われてるみたいですが、独特の音作りによって「これでしか出せない」表現をすることが可能になるそうです。
掴みどころがないというわけではなく、全力で掴み続けて初めてモノになるタイプとか、そんな感じでしょうか。
- おわりに
ただのオタクが調べてみただけなので、実は間違ってるよってパターンがあるかもしれません。
バンドリオタクが楽器欲しくなったときの覚書程度になればと。ちなみに筆者は千聖ベースを欲しがっています。
あと、本記事のモデル使ってるユーザがいたとしても(バンドリモデルはともかく)この楽器持ってたからバンドリファンってことはないと思うので、心のなかでテンション上げる程度にしましょう。
現状ポッピンパーティとロゼリアだけですが、他のコラボモデルが今後普通に出るかもしれないので購入は計画的に。
(※)リンク切れ等一部訂正しました
Honda PCX125 契約しました
今回はバイクの話です。
大学生活で忙しい部分は超えたので、何か新しく趣味になるものを始めよう。と思いたち、予てより興味があったバイクに手を出してみたいなという欲がありました。
そんな最中、バイクに関係する映画とか漫画を読んでるうちにどんどんボルテージが上がってきてしまい、結果購入まで走ることに。



とりあえず免許を取って(小型二種だったので2週間・6万強で取得できました)どのバイクを買おうかな~と思ったとき、当初3つほど候補がありました。
試乗せずカタログ見ただけですが、簡単に所感と決め手を覚え書きします。
一つ目はHonda・PCX

・大きめの車体、大きめのタイヤ
・高燃費(リッター50km強)
・シャープな見た目
・スピードが出やすい(初速で出遅れない)
・125ccの人気首位
・33万~
シャープな見た目で非常に惹かれた車体です。
「125cc おすすめ」とか検索すると間違いなく上位に出るほど人気がある車種のようです。125ccと言いつつ250ccに迫る加速性能を持つとか。
長所はその走行性能と見た目、弱点はメットインの微妙なサイズと大きさから来る駐輪スペースの確保です。

・コンパクトなサイズ感、軽さ(100kg)
・高燃費(リッター55km)
・街乗りに最適化された走行感
・2017年発の新定番モデル
・23万~
ヤマハの125cc新定番モデルの車体です。特筆すべきはそのサイズ感と軽さ。
乗り心地に関して随所に意匠があるようで、長距離乗っても疲れないのが売りらしいです。価格も低めでコスパ良。
調べているときに「SEの人が乗ってそうな車体」とか言われていたのが印象深い。
長所は安さとサイズ、短所は驚くことにほぼ無し。非常に完成度が高いスクーターのようです。
個人的にはタイヤが10インチなのがちょっとマイナス。
三つ目はHonda・スーパーカブ110

・国内バイク市場最大知名度のカブ
・超燃費(リッター60km強)
・脅威のカスタムラインナップ
・超耐久
おなじみカブです。一見MTに見えて区分はATスクーターと同じというよくわからないバイク。変速があってもクラッチがないからATらしいです。なんじゃそら
特筆点はその燃費と耐久、カスタムの幅。日本どころか世界で一番乗られているバイクだけあって、ママチャリのようなカゴから本格的な改造まで千差万別のカスタムラインナップがあります。
また耐久についても申し分なし。ゲームキューブと比べられるレベルの逸話がたくさんあるようです。
その人気たるや、カブ専門の雑誌まで作られるほど。

欠点はシート下の収納がない点ですかね。それ以外はほぼ無いと思います。
という3つで検討して、今回はPCXに決定しました。
決め手で一番大きなウェイトを占めたのは見た目でした。
あとは、やはり人気車種だけあってネット上の「PCXでツーリングしてきました!」といった記事に惹かれたというのもあります。
というわけで現在納車待ちです。たのしみ。
就活時にメンタルを折られて得た教訓
就職活動してる中でメンタル折れました。
その後紆余曲折あって持ち直し、結果として成功を収めることができましたが、当時を振り返って自戒としたいと思います。
- 簡単なスペック
国立理系大学院生
専攻は神経科学、ニューラルネットワーク、ごちうさ
- なんで失敗しまくったのか
これについては、自分の中で1つの結論が出ました。
いい部分も悪い部分も、「自分ではない場所」に理由を見出していたことが一つの失敗要因だったなと深く反省しています。
うまく行けば「学歴のおかげ」「研究テーマがトレンドだから」「○○の学問を学んでいた」
うまく行かなければ「学歴のせい」「面接官との相性が悪かった」「研究の説明が難しかった」
など。
俯瞰した目線であれば一種の責任転嫁のように感じるのですが、当時はそれらがすべて自分の起因するものと考えていました。
例えば、研究テーマの受けがいいとかどうか、という部分の場合。
「このテーマを選んだ自分」が主役ではなく、「会社に認められるテーマ」が主役として考えてしまう感じですね。
学問でもそうです。本来就活というものは「その学問を学んだ自分」を売り出す場なのですが、学問がいかに凄いかという説明に終始していた。
いわば、「技術が分かる自分の魅力」ではなく、「技術の魅力」そのものをセールスしていたようなものです。それでは受かるはずがない。
学んだこと、身につけたスキルこそが主役であり、自分はそれ飾る黒子であるという誤解。今思い返すとこれは、主体性を失っていた状態だなと分析できます。
これで通過しても、「やっぱ技術(学問)はすごいなあ」となるだけで、自分の自信には全く結びつきません。
そして、それで祈られた場合は結構なダメージを受けます。「学んだことやスキルで勝負している」と考えているのに、それが認められなければその部分が全否定されたと短絡的な結論に至ってしまいます。
そういった経験を多くしてしまうと、最終的に「俺には何も残ってない~もうだめだぁ」という状態になり、ますます主体性を失っていきます。
「学生時代は必死こいて勉強して」「技術を身に着けた」にもかかわらず、そを否定されちゃ自分の学生生活って何だったの…と感じてしまうのも無理はないのです。
特に、それ以外に自信を持てていない場合だとそれを頼りに就活することになっているはずなので、ダブルパンチで自信を喪失します。
そこでメンタルをへし折られた感じですね。図1と2に簡単に自分がやってた就活の歪さを示します。

図1 正しい就活のあるべき姿

図2 自分の就活の姿
無論、図2のようなやり方で上手くいく桁違いのスキルを持っている方も居るでしょうが、自分はそうではなかった。
そりゃそうですよね。メーカーにニューラルネットワークの話をいくら説いても、「うん、知ってるけど」みたいに思われるだけです。
「自分は」じゃなくて、「自分が身につけたスキルは」が主語になっていたんですね。いわば、アピールポイントと自分自身が完全に乖離していたわけです。
スキル面で言えば、会社員はプロなのでそれ以上の方がゴロゴロ居るわけです。そこは十分条件であって、必要条件ではないんですね。
でも、それを頼りにしてしまった。そうすると、祈られた場合に図3,図4のような形で差が出ます。
特に自分の経験や人間性に自信がないのでスキルで就活する~とか考えてる場合は顕著で、もう本当に鬱まっしぐらです。ヤバいです。今だから言いますが当時はかなり精神安定剤に世話になりました。
今思うと、保身意識だったんですね。 全部を出して否定されることが怖いから、小出しにしてアクションしよう。傷つきたくないから、本心は隠しておこう。
そんなことを意識はしていませんでしたが、思い返すと潜在意識でそんなことを考えていたんだと思います。

図3 祈られたときにあるべきメンタル

図4 祈られたときのダメな考え方
図4のような考え方だと、自信が頼りにしていた柱がポッキリ折られるので目の前が真っ暗になったような感覚になります。
さらに、図1のような形で就活をしている人に対して技術や学問では負けていないという自負があればあるほど傷跡は深くなります。
大学で学ぶような学問上においては、成績が低いことはおおむね「勉強が足りなかった」で片付けられます。さらに突き詰めると「公式を覚えていなかった」「集中力を無くし計算を間違えた」「当てはめるべき定理を知らなかった」のように、ミクロな原因が沢山浮かび上がります。
試験では、それを一つ一つ丁寧に直していけば評価は確実に上がります。言い換えると、「評価が悪い原因」と「改善方法」が直線的に繋がっている状態です。
これを就活のような人と人のコミュニケーションに求めてしまうことが一つの敗因だったんですね。
本当は複雑な要素が複合して最終的に評価されているのにも関わらず、短絡的にその原因を自信のあるスキルの不足と捉えてしまう。
ある程度自信のある技術や学問をベースに、経験や人間性をアピールすれば良い話だったんです。
そこに気づくまでが長かったですね。
逆説的ですが、合格したときのメンタル回復もこの2つの考え方によって大きく差が出ます。図5,6を見てください。

図5 健全な受け取り方

図6 ダメな受け取り方
図5のように、自分全体として魅力をアピールしている場合は選考を通過した際に自己肯定感、自己効力感に包まれ「よし、次もがんばるぞ!」となることが期待できるかと思います。
しかしながら、自分ではなくスキルをアピールしている感覚では、図6のように選考を通過しても自分自身の自己肯定感には一つも結びつきません。卑屈ですね~
祈られるたびにメンタルがすり減るのに、合格しても回復しない。超ハードモードな精神状況になることは予想に難くないと思います。
もしこれから就活を始める人は、こういう考えにならないよう気をつけていただければと思います。いやなっても良いんですが、メンタルを傷つけないような形の捉え方ができるようにしておいたほうが良いです。
- 逆に良かったこと
これは、メンタルを折られる折られないではなく、いい部分も悪い部分も「自分ではない場所」に理由を見出すことのメリットを少し挙げたいと思います。
この考え方によるメリットは、以下の一つにつきます。
「エントリーシートが通りやすいこと」
就職活動と自分が完全に切り離されているので、記憶や心情に関わらずスラスラ書けます。
人間性や経験では勝負しないと決め込んでいるので、「理想の自分」を作り上げてそれを書くだけです。実際自分はESではほとんど落ちませんでした。だいたい面接で見抜かれましたが。
でも全くオススメはしません。そんなことで書類を通過しても、面接で交通費をかけて落とされるだけです。
しかも上のような考え方とセットで凹むだけです。
就活の交通費だけで10万円くらい飛びましたが、上の原因に気がつくまでは成果はなかったです。参考までに。
- 考え方が変わったきっかけ
就活中は、上のような心理状態で視野が狭窄しており、なかなかにメンタルがヤバイ状態でした。
その中でどうやって回復したかというと、やはり他人にまず打ち明けることです。親でも友人でも、話を聞いてくれる人に理解してもらいましょう。
友人に似た状況の方が居て、悩んでいるそうだ…という場合は上のような傾向がないか教えてあげてください。あと頭ごなしの否定は逆効果なので抑えてね。
加えて言うと、そういった状況下では一日中過度の緊張に置かれており、神経バランスが崩れている可能性が高いです。
その場合は、月並みな経験ですが涙を流すことが効果的です。 涙にはストレス物質の副腎皮質ホルモンを排出する働きがある*1ので、流してスッキリするのが良いと思います。
自分は上の2つで思考のリセットを図り、自己分析をやり直して自己アピールを練り直しました。
「地に足が着かないとはこのことか」と実感したことを覚えています。
約一週間の休養を経て、就活を再開しました。
そうするとあっさり就活を終えられました。紆余曲折でしたね。
- オススメ書籍
その後就活を再開するにあたって、いくつか本を読み直しました。特に参考になった1冊について、以下に紹介します。

就活とは少し縁のないタイトルに見えますが、その実「こういう人材を会社は必要としている」というテーマで読み解くことができる名著です。
優秀な人材の条件とは?というテーマと、そうなるために必要なものは?というようなことが書かれています。
さらに言うと、ビジネスの場における上述のような「ダメなマインド」が、わかりやすい例を用いて書かれています。
就活時点でこの本に最初に出会っていればな~、と思うばかりです。オススメですよ。(筆者は回し者ではないです)
- 最後に
これが 就活している人全部に当てはまるなんてそんなことはないと思います。
ただ、理系院生でスキルもあるはずなのになんで全然うまくいかないの?ってケースであれば、こういう穴に陥ってる可能性が高いと思います。
就活苦に自殺とか馬鹿な考えやめてくださいね。ホントに。喉元過ぎればなんとやらです。
自分もそうでしたが一瞬でも頭を過ぎったことが後悔するレベルです。
どこかで誰かの参考になれば幸いです。
*1:1985, William H. Frey ,Crying: The Mystery of Tears, Winston Pr